Abstract
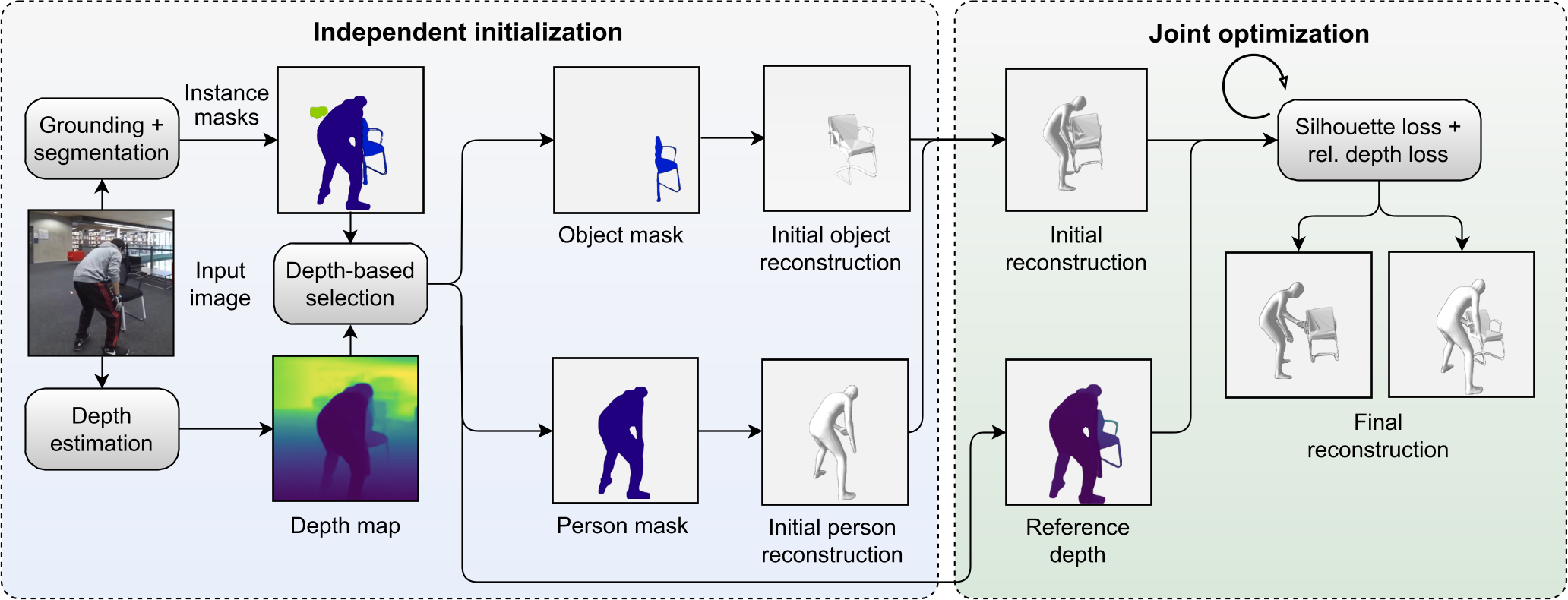
We present ROMEO, a method for reconstructing 3D human-object interaction models from images. Depth-size ambiguities caused by unknown object and human sizes make the joint reconstruction of humans and objects into a plausible configuration matching the observed image a difficult task. Data-driven methods struggle with reconstructing 3D human-object interaction models when it comes to unseen object categories or object shapes, due to the difficulty of obtaining sufficient and diverse 3D training data, and often even of acquiring object meshes for training. To address these challenges, we propose ROMEO, a novel method that does not require any manual human-object contact annotations or 3D data supervision. ROMEO integrates the flexibility of optimization-based methods and the effectiveness of foundation models with large modeling capacity in a plug-and-play fashion. It further incorporates a novel depth-based loss term and largely simplifies the optimization objective of previous methods, eliminating the requirement for manual annotations of contacts and object scales and rendering object-category–specific parameter finetuning unnecessary. We quantify the improvement of ROMEO over existing state-of-the-art methods on two human-object interaction datasets, BEHAVE and InterCap, both quantitatively and qualitatively. We further demonstrate the generalization ability of ROMEO on in-the-wild images.
Example outputs

We visualize input images, initial scene reconstructions showing strong depth-size ambiguities when viewed from different viewpoints, and improved final reconstructions after our joint optimization step reasoning about the human-object relationships using depth estimation.
Baseline comparison

We compare the results of our method ROMEO with PHOSA (Zhang et al., 2020) on the BEHAVE dataset. We show front and side views of the initial results and the final results after joint optimization of each method. Our joint optimization improves the initial estimations in recovering plausible contacts with more plausible depth relationships between humans and objects.
BibTeX
@inproceedings{
gavryushin2024romeo,
title={ROMEO: Revisiting Optimization Methods for Reconstructing 3D Human-Object Interaction Models From Images},
author={Gavryushin, Alexey and Liu, Yifei and Huang, Daoji and Kuo, Yen-Ling and Valentin, Julien and van Gool, Luc and Hilliges, Otmar and Wang, Xi},
booktitle={T-CAP Workshop at ECCV 2024},
year={2024},
url={https://romeo.github.io/}
}